Stateless
The Stateless requirement is REST's second constraint. Fielding writes:
"We next add a constraint to the client-server interaction: communication must be stateless in nature, as in the client-stateless-server (CSS) style of Section 3.4.3 (Figure 5-3), such that each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server. Session state is therefore kept entirely on the client."
To see the stateless requirement more clearly I'll review HTTP. Here's an example of a HTTP 1.1 request and response.
GET http://www.eienet.com.au/ HTTP 1.1
...
200 OK
...
The request encodes the full description of what the client is requesting in the URI and HTTP GET verb. To align with REST, BORED requires a similar location specifier. Let's assume a URI for now, however, to support embedded devices this will need to be more flexible.
To satisfy the stateless constraint, the following parts of BORED are required in the request:
prefix - BORED
version
request identifier
location - URI location or
other location type.
....
message
-- message meta data.
-- message - request data.
---- operation - GET,META,POST,METHOD,etc
---- message data
To meet the stateless requirement the BORED protocol includes the location and full request data.
In the case of a binary protocol an interesting addition is the inclusion of "message meta data". This is Argot specific however can be extended to any binary system that has a meta data definition. In the Argot case the meta data specifies the data structures of the data in the message.
The “message meta data” describes the message data, however, at this point there's no meta data to describe the actual request structure. To understand how BORED will solve this it is worth introducing the concept of an Argot Message Format. The Argot Message Format is designed to be completely self defining. Here's a short description from the Argot Programmer's guide.
Argot Message Files & Dictionaries
Argot message files are binary encoded files that provide the specification of their data with the data. An Argot file contains three parts; a meta dictionary, a data dictionary and the data.
The Argot Message Format allows the full specification of the data to be transferred with the data. This requires no external definition of the data. For an application to be able to read the file its type library must contain all the data types used in the file. A Type Map is generated from the data dictionary portion of the file to read the data. The general format of the file is:
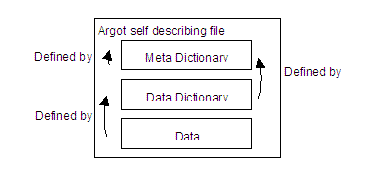
The receiver of an Argot enabled file is able to read the dictionary and compare the data types of its own dictionary with that of the files. Once the types of the file dictionary have been matched with that of the application reading the file, the data can be read. This completely removes the need for a static common domain schema. Each application and file in effect contains its own schema.
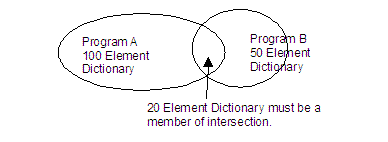
This can be re-illustrated using the following venn diagram:
The process of reading a file involves:
- Binary compare of meta dictionary map. The very first dictionary map of the meta dictionary is the core met dictionary. The only way to read this entry is by performing a binary compare. These are the base dictionary items used to describe new items. Please refer to the meta dictionary reference section for details of the core meta dictionary.
- Build and read Meta dictionary. The rest of the meta dictionary is read and mapped between the application and file.
- Read the Data dictionary. Using the Type Map produced from entries in the Meta Dictionary the Data dictionary is read. A Data dictionary type map is created based on the types identified.
- Read the Data. Using the Data dictionary type map the actual data of the file is read.
The argot message format can be used anywhere that a data buffer can be transferred. In files, message oriented middleware, email, etc.
It would be easy to simply use the Argot Message Format as the full request structure to be delivered to the server. However, carrying the 'meta dictionary' with each and every request adds a lot of overhead. This would also hide the contents of the request data requiring a cache/proxy to read the meta dictionary, data dictionary and data before it can understand the request.
The solution used in BORED is to use the version information of the protocol as a monica for a data dictionary. When a server receives a request it uses the BORED protocol version to choose the corresponding data dictionary. This is like having the meta dictionary and data dictionary of the request at the start of every request. The request and response BORED message are themselves specified in this data dictionary.
The BORED request message however also requires a meta data section for times when the meta data for the request does not include data required by the object receiver. The message data dictionary expands on the request data dictionary to include elements required by the message.
Logically this looks as follows:
[ meta dictionary ] [ request data dictionary ]
---- [ request ... [ message [ message data dictionary] [data ]] ... ]
This allows the Request to logically contain the full meta dictionary, data dictionary, and data for the full BORED request in every message without the overhead of the full meta dictionary and data dictionary.
Using the above method has a drawback that the "request data dictionary" must define every aspect of the request message structure. This includes, security, cache information formats, header formats, and others. This creates an issue for very small devices that only support a subset of the request headers. A solution to this is to break the "request data dictionary" into parts. The client and server can then identify in their request and response the parts of the request data dictionary it supports. For simplicity the parts supported can be indicated via a bit-flag in the version part of the header. For instance, the version header could use three 8-bit flags. The first two would be the major and minor version with the third being the bit-flag for the parts of the request data dictionary supported.
Building on the last post, the request structure header now looks like for the request:
prefix – BOREDand response:
version
dictionary parts
request identifier
...
prefix - BORED
version
dictionary parts
available request slots
request identifier
...
Delivering the stateless constraint using a binary protocol has required developing a few tricks. In particular using the request version number as a key to meta dictionary and request data dictionary has allowed the solution to deliver a technically correct construct and still delivered the ability to reduce the amount of network traffic for each request/response. Using the bit-flag for specifying the parts request data dictionary supported has also allows the solution to scale from small devices to large full features systems.

No comments:
Post a Comment
Note: only a member of this blog may post a comment.